Reinforcement Learning from Human Feedback: Challenges & Limitations
The Gap Between Humans and Machines Is ___Подробнее

The Limits of AI: Why Morality Is IntuitiveПодробнее

Randomly Sampled Language Reasoning Problems Reveal Limits of LLMsПодробнее

AI Model Self-Improvement: Progress and Challenges. #artificialintelligance #airesearch #aitalkПодробнее

Reinforcement Learning from Human Feedback: Challenges & LimitationsПодробнее

Panel Discussion: Open Problems in the Theory of Deep LearningПодробнее

Reinforcement Learning from Human Feedback (RLHF) ExplainedПодробнее

LLM Chronicles #5.6: Limitations & Challenges of LLMsПодробнее

33 - RLHF Problems with Scott EmmonsПодробнее

30.01.2024 Open Problems and Fundamental Limitations ofReinforcement Learning from Human FeedbackПодробнее

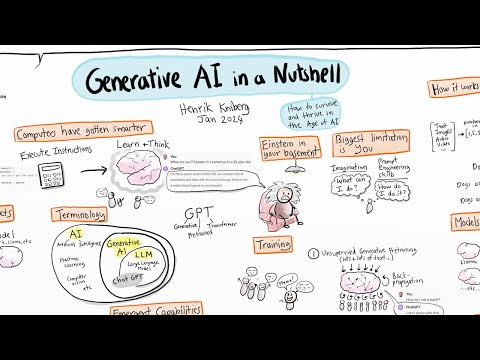
Generative AI in a Nutshell - how to survive and thrive in the age of AIПодробнее
Open Problems and Fundamental Limitations of Reinforcement Learning from Human FeedbackПодробнее

Objective Mismatch in Reinforcement Learning from Human FeedbackПодробнее

What You've Heard About Q* is Bull**** - It's Not AGIПодробнее

Lessons from reinforcement learning from human feedback | Stephen Casper | EAG Boston 23Подробнее

The State of AI: Opportunities, Limitations and Dangers - Lecture by Amnon ShashuaПодробнее

Stanford CS224N | 2023 | Lecture 10 - Prompting, Reinforcement Learning from Human FeedbackПодробнее

AI Seminar Series: Stephen Montes CasperПодробнее

The HUGE Problems with RLHF for AI (Paper Breakdown)Подробнее

Unveiling AI's Secrets: The Truth About Machine Learning | vanAmsen Explain PodcastПодробнее
