Dynamic Layer Skipping for Transformers

Dynamic Layer Skipping Boosting Transformer PerformanceПодробнее

Amanuel Mersha - DynamicViT: Making Vision Transformer Faster Throuhh Layer SkippingПодробнее

Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal ThinkingПодробнее

No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-based Language ModelsПодробнее

Boosting vision transformers for image retrievalПодробнее

What are Transformers (Machine Learning Model)?Подробнее

What is Mutli-Head Attention in Transformer Neural Networks?Подробнее

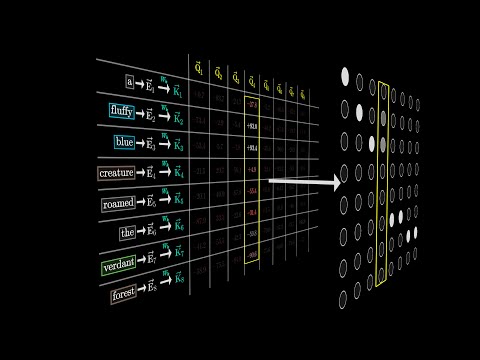
Attention in transformers, step-by-step | Deep Learning Chapter 6Подробнее
CoLa: Dynamic Depth for LLMsПодробнее

torch.nn.TransformerEncoderLayer - Part 3 - Transformer Layer NormalizationПодробнее

Simplest explanation of Layer Normalization in TransformersПодробнее

Transformers | Basics of TransformersПодробнее

Layer Normalization by handПодробнее

Homemade Transformer Robot 🔥 #Robot #ShortsПодробнее

[MLArchSys 2024] Lightweight Vision Transformers for Low Energy Edge InferenceПодробнее
![[MLArchSys 2024] Lightweight Vision Transformers for Low Energy Edge Inference](https://img.youtube.com/vi/lv0lDBaOvWA/0.jpg)
Attention for Neural Networks, Clearly Explained!!!Подробнее

Training a Transformer Model from Scratch: Full Guide with Attention, Encoding, and Layers.Подробнее

Transformers | how attention relates to TransformersПодробнее
