Dynamic Layer Skipping Boosting Transformer Performance

Amanuel Mersha - DynamicViT: Making Vision Transformer Faster Throuhh Layer SkippingПодробнее

Boosting vision transformers for image retrievalПодробнее

День - 329. Гантеля за каждый лайк | Прими участие, стань лучшей версией себяПодробнее

Sparse is Enough in Scaling Transformers (aka Terraformer) | ML Research Paper ExplainedПодробнее

Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal ThinkingПодробнее

Transformers, the tech behind LLMs | Deep Learning Chapter 5Подробнее

[T-Fixup] Improving Transformer Optimization Through Better Initialization | AISCПодробнее
![[T-Fixup] Improving Transformer Optimization Through Better Initialization | AISC](https://img.youtube.com/vi/EpxilvBvAeQ/0.jpg)
[MLArchSys 2024] Lightweight Vision Transformers for Low Energy Edge InferenceПодробнее
![[MLArchSys 2024] Lightweight Vision Transformers for Low Energy Edge Inference](https://img.youtube.com/vi/lv0lDBaOvWA/0.jpg)
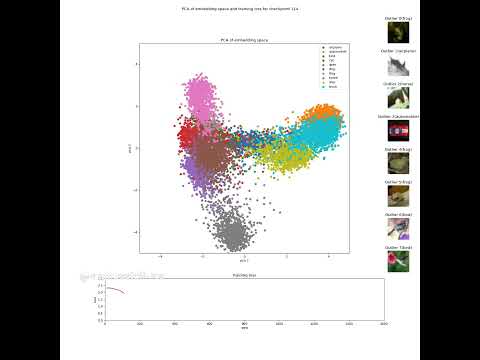
Visualization of embeddings with PCA during machine learning (fine-tuning) of a Vision TransformerПодробнее
What is Mutli-Head Attention in Transformer Neural Networks?Подробнее

Deep dive - Better Attention layers for Transformer modelsПодробнее

Blowing up the Transformer Encoder!Подробнее

LLM2 Module 1 - Transformers | 1.3 The Transformer BlockПодробнее

How Transformers and Hugging Face boost your ML workflowsПодробнее

Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRAПодробнее

What are Transformers (Machine Learning Model)?Подробнее

Training a Transformer Model from Scratch: Full Guide with Attention, Encoding, and Layers.Подробнее

Transformers | Basics of TransformersПодробнее

Transformers | how attention relates to TransformersПодробнее
