Tutorial 11: Decoder in Transformer models - Part 4

Decoder-Only Transformers, ChatGPTs specific Transformer, Clearly Explained!!!Подробнее

Decoder-only inference: a step-by-step deep diveПодробнее

Transformer models: DecodersПодробнее

Attention in transformers, step-by-step | Deep Learning Chapter 6Подробнее
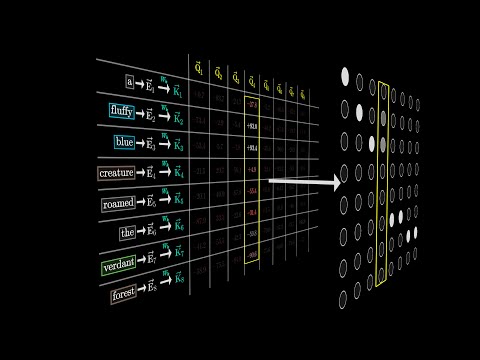
Coding-Decoding #ShortsПодробнее

L11.5-2: Sequence-to-Sequence Learning, using a Transformer encoder/decoderПодробнее

How Cross Attention Powers Translation in Transformers | Encoder-Decoder ExplainedПодробнее

Explore the Power of the T5 Encoder-Decoder Model | NLP & Transformers ExplainedПодробнее

Ep1 - How to make Transformer (Encoder Decoder) Models Production Ready?FAST, COMPACT and ACCURATEПодробнее

Transformer Encoder Explained | Pre-Training and Fine-Tuning | Like BERT | Attention MechanismПодробнее

Why Transformer over Recurrent Neural NetworksПодробнее
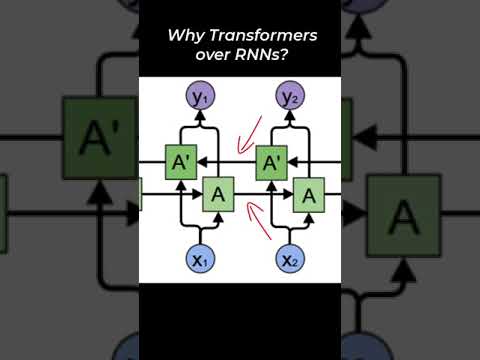
Transformers, explained: Understand the model behind GPT, BERT, and T5Подробнее

Transformers | how attention relates to TransformersПодробнее

BERT Networks in 60 secondsПодробнее
What is Self Attention in Transformer Neural Networks?Подробнее

China Tab Unlock Pattren Pin Code remove#mirmobilesolutionsПодробнее
🔥🤖 BERT Killed Old-School NLP! 💀📖 Why Encoder-Only Models Changed Everything ⚡🧠✨ [Part 4/6]Подробнее
![🔥🤖 BERT Killed Old-School NLP! 💀📖 Why Encoder-Only Models Changed Everything ⚡🧠✨ [Part 4/6]](https://img.youtube.com/vi/DFTy1FxcrrI/0.jpg)
Blowing up Transformer Decoder architectureПодробнее
