Self Attention in Transformer Neural Networks (with Code!)
Deep Learning 7 [Even Semester 2025 Telyu] - Attention and TransformerПодробнее
![Deep Learning 7 [Even Semester 2025 Telyu] - Attention and Transformer](https://img.youtube.com/vi/fT0c4lC5I_g/0.jpg)
How to Build a GPT Model from Scratch | Attention is All You Need Explained | Follow Along | Part 6Подробнее
Please Pay Attention: Understanding Self-Attention Mechanism with Code | LLM Series Ep. 1Подробнее

How to Build a GPT Model from Scratch | Attention is All You Need Explained | Follow Along | Part 5Подробнее
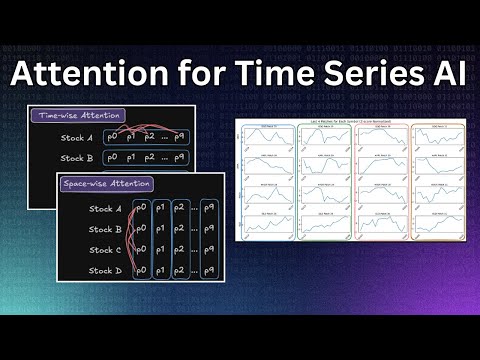
Factorized Self Attention Explained for Time Series AIПодробнее
Natural Language Processing:Transformer layer architecture und Key query value calculationПодробнее

How to Build a GPT Model from Scratch | Attention is All You Need Explained | Follow Along | Part 4Подробнее
Attention Mechanism in PyTorch Explained | Build It From Scratch!Подробнее

Lets Reproduce the Vision Transformer on ImageNetПодробнее
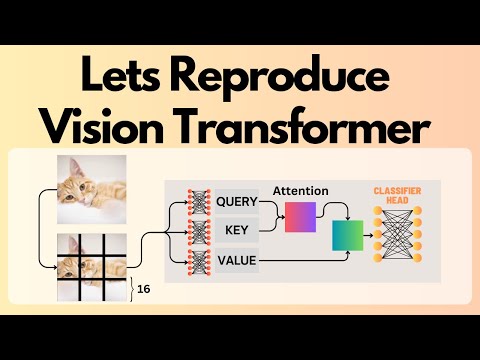
Image Detection | Image Classification | Compact Convolutional Transformer | Deep Learning ProjectПодробнее

Code DeepSeek V3 From Scratch in Python - Full CourseПодробнее

GenAI: LLM Learning Series –Transformer Attention Concepts Part-1Подробнее

Understand & Code DeepSeek V3 From Scratch - Full CourseПодробнее

Lecture 79# Multi-Head Attention (Encoder-Decoder Attention) in Transformers | Deep LearningПодробнее
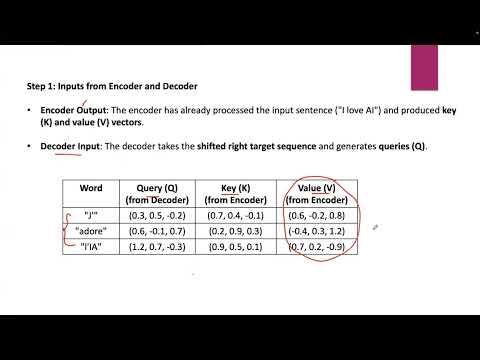
The Secrets Behind How Large Language Models ThinkПодробнее

Build ChatGPT from Scratch with Tensorflow - Tamil #chatgpt #ai #aiprojectsПодробнее

Transformer models and bert model overviewПодробнее

LLM mastery 03 transformer attention all you needПодробнее

Learn TRANSFORMERS ... in 6 MinsПодробнее

How Transformer Encoders ACTUALLY Work | The AI Technology Powering ChatGPT ExplainedПодробнее
