LLMs | Intro to Transformer: Positional Encoding and Layer Normalization | Lec 6.2

Transformers (how LLMs work) explained visually | DL5Подробнее

Transformer Neural Networks, ChatGPT's foundation, Clearly Explained!!!Подробнее
What are Transformers (Machine Learning Model)?Подробнее

Illustrated Guide to Transformers Neural Network: A step by step explanationПодробнее
Positional embeddings in transformers EXPLAINED | Demystifying positional encodings.Подробнее

Transformers, explained: Understand the model behind GPT, BERT, and T5Подробнее

RoPE (Rotary positional embeddings) explained: The positional workhorse of modern LLMsПодробнее

GenAI: LLM Learning Series –Transformer Attention Concepts Part-1Подробнее

Attention mechanism: OverviewПодробнее

Large Language Models explained brieflyПодробнее

Positional Encoding in Transformer Neural Networks ExplainedПодробнее

What is Positional Encoding in Transformer?Подробнее

Positional Encoding in Transformers | Deep LearningПодробнее

Position Encoding in Transformer Neural NetworkПодробнее
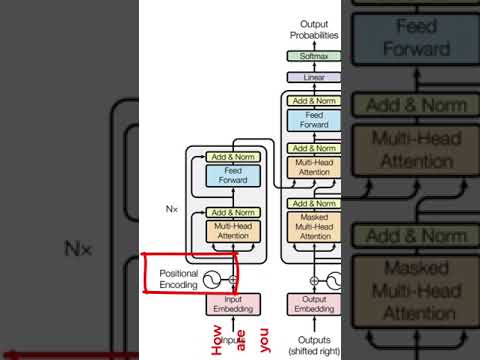
Transformer Positional Embeddings With A Numerical Example.Подробнее

torch.nn.TransformerEncoderLayer - Part 5 - Transformer Encoder Second Layer NormalizationПодробнее

What is Mutli-Head Attention in Transformer Neural Networks?Подробнее

MIT 6.S191: Recurrent Neural Networks, Transformers, and AttentionПодробнее

torch.nn.TransformerEncoderLayer - Part 3 - Transformer Layer NormalizationПодробнее
